
The most common mistake is hiring someone to respond to incidents instead of someone to engineer them out of existence. A firefighter keeps the lights on. An SRE makes sure there's nothing left to catch fire.
Your Klysera SRE treats reliability as a software problem, not an operations chore — building the redundancy, the error budgets, and the automated recovery systems that let your team ship fast without gambling on uptime.
Hire site reliability engineers who engineer outages out of existence
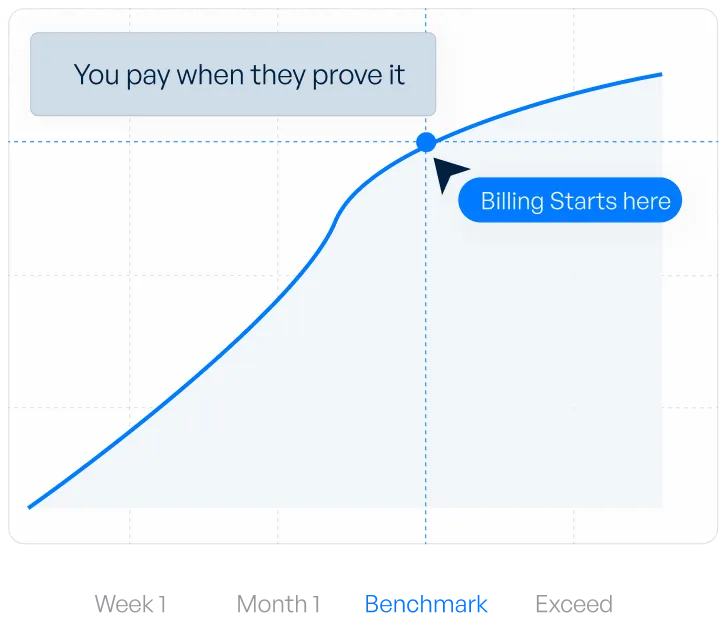
Get matched with vetted AI-native SREs in less than 2 weeks, at up to 60% less than traditional hiring models, on an outcome-based model that ensures you only pay if we hit the desired benchmarks.




Trusted By Global Tech Teams Building The Future




THE FUTURE OF MOBILE ENGINEERING
You don't need a $100,000 ops hire to protect the revenue an outage would cost you.

The majority of companies experience at least one major outage a year and over half of those outages cost more than $100,000. Most teams discover this the expensive way, after the incident, when the postmortem reveals the failure was preventable all along.
A site reliability engineer prevents that outcome before it happens. They build the monitoring, the error budgets, and the automated recovery systems that catch problems before users do.
YOUR SRE ENGINEERING ADVANTAGE
The site reliability engineering
Talent partner your product has been waiting for.
Talent partner your product has been waiting for.
See the Impact Agreement

BUILT FOR THE WAY YOU BUILD
World-class site reliability engineers built around the outcomes that determine whether downtime costs you users or never happens at all.






Incident Response & On-Call
Problem
No Handoff
Scope
Detects issues before users report them, triages by severity, and resolves incidents in minutes, not hours.
Infrastructure as Code & Automation
Problem
No Handoff
Scope
Treats infrastructure as software; version-controlled, tested, and automated, so deployments are repeatable and human error stops being your biggest reliability risk.
Capacity Planning & Scalability
Problem
No Handoff
Scope
Plans ahead for load, tests systems under real-world stress, and designs for graceful degradation, so a traffic spike becomes a non-event instead of a postmortem.
Postmortems & Systemic Learning
Problem
No Handoff
Scope
Runs blameless postmortems that turn incidents into permanent fixes so that the same outage doesn't happen twice.
SUCCESS IN NUMBERS
The best return on your engineering investment.
Companies that hire through Klysera get a measurable shift in how their infrastructure performs, what it costs, and how fast their team can ship on top of it.
60%
Cost savings compared to traditional hiring models
5-Point
IKE framework every engineer is stress-tested against to ensure they meet the set benchmarks
$0
Is our fee if your engineer doesn't hit the benchmarks we agreed before they started.
100%
Of all Klysera's engagements are outcome-based, so you only pay for results.
THE FUTURE OF SRE ENGINEERING
We Built The Framework To Get You The Rarest Type of Builders
Most founder conversations with talent partners feel like being sold to. Ours don't. Here's exactly what happens from the moment you book to the moment your engineer is working on your product:


OUR SERVICES
Great site reliability engineering is less about reacting faster and more about making sure there's less to react to.
From your first SLO to the incident that never happens, every Klysera SRE shows up ready to own the work that determines whether downtime costs you users or never costs you anything at all.
Reliability Architecture & Planning
SLO, SLI & error budget definition
Failover & redundancy architecture
Capacity planning & load testing
Disaster recovery planning
Observability & Incident Response
Monitoring, alerting & dashboard design
On-call rotation & incident triage systems
Root cause analysis & rapid resolution
Blameless postmortem process design
Automation & Infrastructure as Code
Infrastructure as code (Terraform, Ansible, Pulumi)
CI/CD pipeline design & deployment automation
Self-healing system design
Toil elimination & process automation
Security & Production Operations
Runtime threat detection & vulnerability remediation
Container orchestration & multi-cloud visibility
Change management & safe deployment practices
Compliance & availability controls (SOC 2, ISO 27001)
KLYSERA VS. THE ALTERNATIVES
Hiring or outsourcing? Neither.
Work with world-class AI-native SRE engineers who are fully vetted, enabled, and backed by a guarantee built around your outcomes.
Klysera
We define what success looks like together — specific, measurable outcomes your engineer is expected to deliver.
Traditional staffing
They hand you resumes and hope for the best. No accountability after placement.
In-house hiring
Full control, but slow, expensive, and you're gambling on interviews alone.
Outsourced dev shops
They build it for you, but you lose control, context, and the ability to iterate on your own terms.



AI-Native Talent
Klysera

Traditional staffing

In-house hiring
Outsourced dev shops
End-to-End Ownership
Klysera
Traditional staffing

In-house hiring
Outsourced dev shops
Performance Guarantee
Klysera
Traditional staffing
In-house hiring
Outsourced dev shops
Ongoing Enablement
Klysera
Traditional staffing
In-house hiring
Outsourced dev shops
Cost Efficiency
Klysera
Traditional staffing
In-house hiring
Outsourced dev shops
Impact Agreement
Klysera
Traditional staffing
In-house hiring
Outsourced dev shops
OUR WORK
Here's what happens when a site reliability engineer treats your infrastructure like it's their own.
"Our cloud bill had tripled in 18 months and nobody could tell me why. The Klysera engineer we brought in audited everything, cut $38K in monthly spend, and rebuilt our deployment pipeline in six weeks. We went from shipping fortnightly to shipping daily. That's not an infrastructure win — that's a product win."
Daniel R. · CTO
Series B SaaS · Remote
"We had 14 infrastructure vulnerabilities flagged two weeks before our biggest enterprise sales call. Klysera's cloud engineer closed every one and had our compliance documentation ready before the meeting. We closed the client. That engineer paid for themselves in one deal."
Sarah M. · CEO
AI Startup · London
"We had no infrastructure, no DevOps, nothing. Just a product that needed to exist. Klysera built the entire cloud foundation from scratch — architecture, CI/CD, security baseline — and stayed with us through the seed round. Investors were asking about our technical foundation. For the first time, we had a real answer."
Yoav B. · VP Engineering
Fintech · Tel Aviv
"We were burning through compute budget and our unit economics didn't make sense. The inference infrastructure Klysera built reduced our per-request cost by 64%. That number is what got us to Series A. I'm not exaggerating."
Noa T. · Founder
Pre-Seed · Remote
OUR DIFFERENCE
Klysera is built for founders who refuse to settle.
Accountable:
We monitor delivery against the benchmarks we agreed before work began, step in when things drift, and stay accountable for outcomes long after the onboarding call is over.
Precise:
We match you to the engineer whose specific experience maps to your specific inflection point in a company that looked like yours.
Enabling
Every Klysera engineer arrives with more than technical skills. They arrive equipped with the frameworks, tooling, and ongoing support to deliver from day one and stay consistent throughout the engagement.
Seamless
You always know where your engineer stands, what they're working on, and whether the benchmarks are being hit.
YOUR PRODUCT DESERVES BETTER
We only work with the best engineers to ensure maximum product quality
Fewer than one in five engineers who enter the Klysera assessment pass the IKE standard, because owning retention, making the right platform call, navigating App Store compliance, and integrating on-device AI simultaneously is a specific capability most hiring processes never screen for.








A NEW STANDARD FOR YOUR PRODUCT
You didn't build something worth scaling just to watch it hit a ceiling your architecture can't support
There's a better way to build. And it's not another job board search, another agency retainer that disappears when the performance ceiling appears, or another freelancer who makes the framework call based on what they know rather than what your product needs.

Experience a new standard in site reliability engineering.
Let's talk about what you're building and find the engineer who's made those decisions correctly before.
